
L’INP, acronyme de « Interaction to Next Paint », est une métrique de web performance introduite par Google en mai 2022 pour succéder à un autre indicateur de performance, le FID. Disponible en bêta depuis février 2023 via le flag “Expérimental”, elle fait son entrée officielle au sein des Core Web Vitals ce mois-ci, le 12 mars 2024 très précisément.
Dans cet article qui lui est entièrement consacré, nous allons vous expliquer tout ce qu’il faut savoir sur cette métrique de webperf, et notamment comment s’assurer d’être au vert ou, du moins, de s’en rapprocher au maximum. C’est un objectif que vous devez absolument viser dans la mesure où l’INP impacte désormais les Core Web Vitals, qui constituent elles-mêmes un critère de l’algorithme de classement des pages de résultats du moteur de recherche de Google.
Évolution de l’algorithme de Google : une nécessité
Avant de nous plonger pleinement dans les moyens de mesure puis dans l’optimisation de l’INP, il me semble essentiel de revenir sur la question du “pourquoi”. Google et les éditeurs de sites disposent en effet de trois métriques Core Web Vitals qui semblaient répondre à leurs objectifs, n’est-ce pas ? Alors pourquoi introduire, près de quatre années après le coup d’envoi, une nouvelle métrique et venir bousculer les habitudes des éditeurs de sites, agences web et freelances ?
De la notion de pertinence à la mesure de la qualité
Comme nombre d’éditeurs de sites, d’agences web et d’experts SEO, une partie de votre veille consiste probablement à suivre au plus près les mises à jour de l’algorithme de classement des résultats de Google. Historiquement, ces dernières visaient avant tout à s’assurer de la pertinence des contenus via un nombre croissant de mécanismes complémentaires :
- identification des textes de basse qualité (spam notamment), du duplicate content et, plus récemment, des contenus générés par l’IA ;
- amélioration du scoring lié à l’autorité via une détection des techniques de netlinking “non naturelles” : spam, achat de liens, réseaux de sites satellites…
Depuis 2020, Google a complété ses “Core Updates” et autres “Spam Updates” avec un nouveau type de mise à jour visant à estimer la qualité des pages et sites web. Avec elles, le géant américain vise à évaluer le niveau de satisfaction des utilisateurs, et plus seulement la pertinence intrinsèque des contenus et leur popularité. Cette approche orientée UX est, pour lui, la meilleure stratégie pour s’assurer de conserver son leadership dans la recherche en ligne.
Or, évaluer et a fortiori mesurer l’Expérience Utilisateur n’a rien de simple : il s’agit d’un vaste domaine qui, dans le web, implique des métiers aussi variés que le webdesign, la sécurité, l’accessibilité ou encore le développement front-end. C’est dans cette optique que Google a déployé son volet “Page Experience”, qui repose en partie sur les “Core Web Vitals” – que l’on a un temps traduit en français par « Signaux Web essentiels ». Et c’est ce dont nous allons parler maintenant.
Les Core Web Vitals pour mesurer l’Expérience Utilisateur réelle
Les “Core Web Vitals” sont un ensemble de métriques imaginées par les ingénieurs de Google pour mesurer mathématiquement la qualité de l’Expérience Utilisateur. Pour récolter les données chiffrées d’une composante qui, d’un point de vue utilisateur, fait largement intervenir le subconscient et les émotions, ces derniers ont dû définir les bases de ce qu’est concrètement la web performance. Cette démarche leur a permis d’identifier trois composantes clés, chacune matérialisée par une métrique.
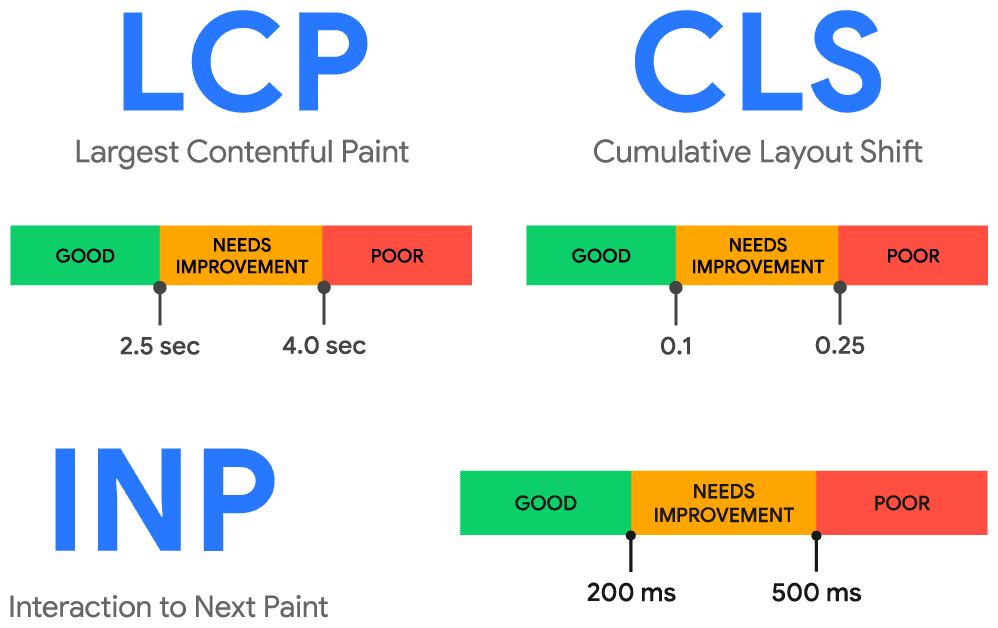
Vitesse perçue : LCP
Le LCP, acronyme de “Largest Contentful Paint”, vise à calculer la vitesse de chargement perçue par les utilisateurs. Si le Speed Index aurait été plus pertinent pour cet exercice, Google a dû composer avec la réalité du terrain en optant pour un indicateur moins coûteux à calculer. C’est la raison pour laquelle le LCP calcule la durée nécessaire pour afficher le principal élément visible dans le viewport au chargement initial d’une page.
Dans les faits, la corrélation entre Speed Index et LCP est importante, faisant du LCP une métrique tout ce qu’il y a de plus pertinente. S’il ne fallait en garder qu’une, c’est incontestablement le LCP qui resterait.
Stabilité visuelle : CLS
Le CLS, acronyme de “Cumulative Layout Shift”, vise à calculer la consistance d’une interface web dans la durée. Il n’y a en effet rien de plus perturbant pour un utilisateur que de naviguer sur une page dans laquelle les éléments se déplacent de façon anarchique. L’objectif est de s’assurer que les interactions avec une page résultent de la volonté de l’utilisateur et non d’une mauvaise manipulation. C’est une excellente façon de mesurer de potentielles frustrations.
L’indicateur joue à nouveau ici parfaitement son rôle, apportant un éclairage précis sur les problématiques techniques des pages.
Réactivité de l’interface : du FID à l’INP
C’est dans le cadre de ce troisième volet que nous entrons dans le vif du sujet. Depuis l’introduction des Core Web Vitals en 2020, la réactivité des pages était calculée via le FID, acronyme de “First Input Delay”. Un indicateur particulièrement explicite puisqu’il se traduit en français par “Premier retard de saisie”, et que c’est assez précisément ce qu’il mesure.
Le FID était toutefois très peu représentatif de l’expérience réelle des utilisateurs sur le plan de la réactivité, et cela pour deux raisons principales :
- il ne mesurait que la première interaction, mais pas les suivantes. Or, les utilisateurs passent en moyenne 90% de leur temps à naviguer dans une page, la première interaction ne représentait ainsi qu’une infime partie de ce qu’ils expérimentent en réalité ;
- il ne mesurait que la latence avant l’exécution d’un JavaScript, et non la latence complète telle qu’elle est perçue par l’utilisateur. Le delta pouvait ainsi être significatif entre les deux, avec un FID largement sous-estimé la plupart du temps : le premier seuil des 100 ms était rarement atteint, faisant perdre à la métrique de son intérêt.
C’est pour corriger ces lacunes qu’a été introduit l’INP, acronyme de “Interaction to Next Paint”. Avec cette nouvelle métrique, on se place du point de vue de l’utilisateur : ce que l’on cherche à obtenir est un résultat visible dans la page, et non plus l’exécution d’une fonction de rappel JavaScript dénuée de sens (un “callback”). Et cela tout au long des sessions de navigation, et plus seulement au chargement des pages.
C’est, au moment où un utilisateur quitte une page web, la valeur maximale qui est prise en compte et devient l’INP du point de vue des Core Web Vitals. Cette approche fait sens dans la mesure où elle vise à s’assurer que le niveau de performance est consistant dans la durée.
Comment mesurer l’INP ?
Comme pour les autres Core Web Vitals, les ingénieurs ont établi une méthodologie précise pour calculer l’INP d’une page. L’objectif est que quel que soit l’outil utilisé, les résultats soient consistants.
Comment est calculé l’INP ?
Contrairement à son prédécesseur FID, l’INP ne peut pour l’instant être obtenu qu’à travers les navigateurs web basés sur Chromium, soit Google Chrome, Microsoft Edge, Opera et le navigateur mobile Samsung. Ni Firefox, ni Safari n’ont accès à une telle API. Voyons maintenant comment la métrique est concrètement calculée.
Trois étapes au lieu d’une
Comme nous l’avons vu précédemment, l’INP va plus loin que le FID en termes de mesure. Lors d’une interaction de type clic, toucher d’un écran tactile ou saisie au clavier (mais pas scroll ni hover), la métrique est calculée en additionnant la durée de trois étapes principales :
- l’input delay, qui englobe notamment le FID et calcule la latence entre une saisie utilisateur et le déclenchement de l’événement correspondant ;
- le traitement de l’interaction en elle-même via JavaScript, CSS ou les fonctions natives du navigateur ;
- l’affichage à l’écran de la page actualisée, ce qui passe par une phase de rendu et de paint (détaillée plus précisément par la suite).
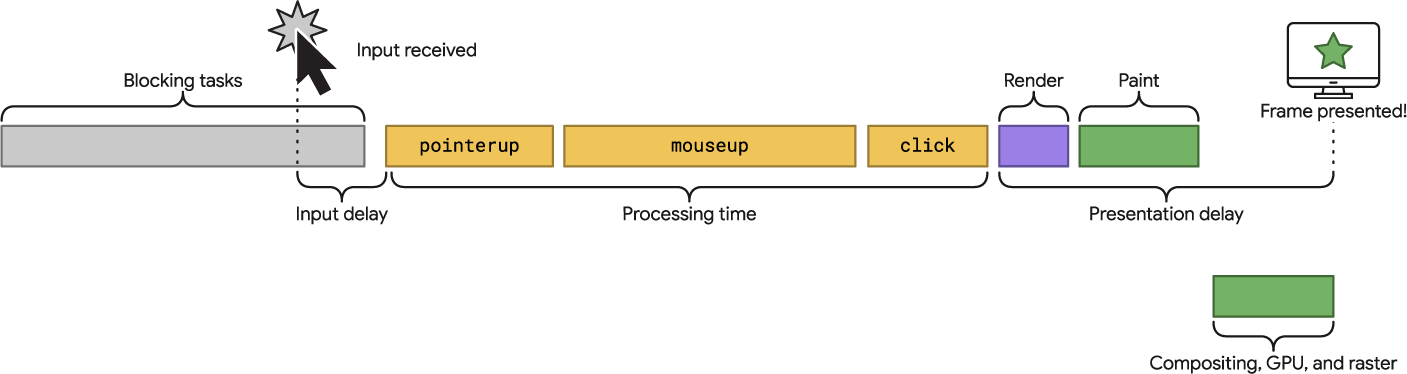
Ces données étant temporelles, l’unité de mesure de l’INP est la milliseconde. Pour offrir une expérience utilisateur de qualité en termes de réactivité, les ingénieurs de Google ont estimé qu’il était nécessaire d’être sous les 200 ms. Le seuil est ainsi plus généreux que pour le FID, ce qui fait sens puisqu’on mesure davantage d’éléments. À l’inverse, dépasser le seuil de 500 ms (une demi-seconde) fait passer l’indicateur en échec.
Une grande variabilité
Nous avons expliqué que l’INP mesurait une somme de latences et de temps de traitement sans détailler pourquoi cela pouvait prendre du temps. La réponse, vous l’avez sous les yeux : c’est votre matériel, et plus spécifiquement la puissance de calcul de votre microprocesseur et la quantité de mémoire vive dont il dispose. L’exécution des JavaScript et le rendu visuel constituent deux opérations extrêmement coûteuses pour un CPU, qui exécute une majorité des traitements dans un seul et même fil de calcul (on parle de “thread” en anglais).
En conséquence, ce dernier arrive rapidement et régulièrement à saturation, ce qui génère les fameuses “Long Tasks” (plus de 50 ms de durée d’exécution). Cela se traduit concrètement par une très grande variabilité dans les métriques collectées auprès des utilisateurs : un visiteur sur desktop n’aura pas le même niveau de performance qu’un mobinaute. Et même entre utilisateurs de smartphones, le système d’exploitation, les paramètres système ou encore le navigateur constituent autant de facteurs de variabilité.

L’objectif de Google étant de fournir des métriques compréhensibles et actionnables par les éditeurs de sites, les données sont systématiquement ventilées entre les utilisateurs mobiles d’un côté et les utilisateurs desktop de l’autre. Un regroupement logique tant l’expérience entre l’une et l’autre de ces familles de terminaux peut différer : dimensions d’écrans, densité de pixels, mode de saisie, niveau d’attention… On est bien face à deux expériences totalement différentes.
75ème percentile sur 28 jours
Au vu de la variété des expériences, il n’est pour la plupart des sites pas envisageable de viser un objectif de 100% de performance, pour l’INP comme pour les autres métriques d’ailleurs. Fort de ce constat, Google a opté pour une approche basée sur des seuils au 75ème percentile. Cela signifie que pour valider l’INP, au moins 75% de vos utilisateurs doivent bénéficier d’un bon INP (sous les 200 ms, donc).
Cette approche fait consensus dans la mesure où elle garantit une bonne représentativité (contrairement au seuil de 50% utilisé précédemment) tout en n’étant pas aussi exigeante que le seuil du 90ème percentile parfois évoqué au sein des équipes de Google. Rien ne motive plus qu’un objectif atteignable.
Lorsqu’on analyse les données d’une url ou d’une Origine dans un rapport fourni par Google, le 75ème percentile est matérialisé par de petites épingles noires. Chacune est surmontée d’une valeur qui correspond au 75ème percentile consolidé pour l’ensemble des utilisateurs.

On notera enfin que pour des questions de coûts de calcul, les données partagées par Google sont lissées sur 28 jours glissants. Cette forme d’inertie rend complexe l’utilisation des données issues des outils officiels de Google pour monitorer la performance. En contrepartie, cela évite l’effet “montagnes russes” qui conduirait à des envois d’alertes massifs à la moindre mise à jour ou vidange de cache.
Avec quels outils mesurer l’INP ?
Comme nous avons commencé à le voir, Google collecte l’INP via son API navigateur Core Web Vitals. Mais est-il le seul à la faire ? Et comment peut-on utiliser de telles données pour piloter un projet web et prendre les bonnes décisions ? Nous allons lister ensemble les outils qui répondent à ces questions.
Le Chrome User Experience Report
Nous avons déjà largement abordé l’écosystème d’outils développé par Google sans pour autant l’introduire. Un manquement corrigé dès à présent avec une présentation de bonne et due forme du “Chrome User Experience Report”, ou “CrUX” en abrégé. L’outil est une gigantesque base de données dans laquelle sont stockées les données de performance collectées auprès des utilisateurs via la fameuse API intégrée au navigateur Google Chrome.
Les données du CrUX sont celles utilisées par Google pour l’ensemble de ses rapports : Core Web Vitals dans la Search Console, section “Découvrez l’expérience de vos utilisateurs” dans les rapports PageSpeed Insights… Ces données étant libres d’accès, elles sont aussi accessibles via des API et BigQuery, ce qui permet d’aller bien au-delà de ce que propose Google en termes de mise en forme et de fraîcheur.
Si vous souhaitez aller au-delà de la maigre interface proposée par Google dans sa Search Console ou accéder aux données récentes, nous vous recommandons l’utilisation d’un outil tiers comme Treo ou Speetals. Ces derniers sont capables de récupérer les données du CrUX pour les mettre en forme de façon plus intelligente, et ainsi profiter de dashboards réellement opérationnels. Ils permettent notamment de filtrer les utilisateurs par origine géographique ou encore de consulter l’historique sur 3 années.
Les données terrain
La grande force du CrUX est son fonctionnement pleinement intégré et automatisé : les données sont collectées quoi qu’il arrive sans sollicitation des éditeurs de sites. Mais ce n’est pas parce que ces données existent inconditionnellement et gratuitement qu’elles doivent être au cœur de votre stratégie d’optimisation ou de monitoring de la webperf.
Il est en effet possible de collecter ces mêmes données via un tag JavaScript, ce qui lève au passage les multiples contraintes inhérentes au CrUX. L’échantillon est notamment élargi, puisqu’un nombre croissant de métriques est disponible au sein de navigateurs comme Safari et Firefox (le LCP notamment depuis la version 122). Selon la configuration adoptée, les outils de “Real User Monitoring” (“RUM”) permettent aussi de creuser de façon pointue les métriques récoltées :
- mise en évidence des visites uniques vs. les visites multi-pages où le cache navigateur améliore significativement la performance ;
- mise en évidence des pages vues mettant à profit le mécanisme de cache amélioré, ou « Back Forward Cache », qui garantit des métriques très basses ;
- mise en évidence des pages avec un état de visibilité masqué : ouvertes dans un onglet masqué, les pages affichent généralement une performance en net retrait ;
- création de groupes de pages pertinents pour une activité donnée. Exemple : pages catégories, pages produits et landing pages SEA pour un site e-commerce.
Côté INP, les outils de type RUM peuvent en complément permettre de récupérer les données d’interactions pour identifier les composants responsables des latences à l’interaction. Cette contextualisation apporte une très grande valeur ajoutée car contrairement au LCP et au CLS, l’INP n’est disponible qu’au sein des données terrain puisqu’il nécessite de naviguer dans les pages.
Pour intégrer une telle fonctionnalité à votre stack technique, vous aurez l’embarras du choix. Les différents outils sur le marché reposent tous sur l’API Performance native, qui permet de récupérer les données des utilisateurs via la méthode JavaScript performance.getEntries() ou via une instance de PerformanceObserver. Dans l’absolu, il est même possible de développer votre propre outil de collecte, de traitement et d’affichage de ces données.
Mais la solution la plus accessible est de se tourner vers une solution SaaS comme Request Metrics, RUMvision, DebugBear, Dynatrace, New Relic, Raygun ou encore Contentsquare. Gardez toutefois en tête que ces derniers nécessitent le déploiement d’un JavaScript en front-end… et qu’ils peuvent ainsi être générateurs de Blocking Time et contribuer à la hausse de votre INP. À vous de voir, donc, si le jeu en vaut la chandelle.
Les données synthétiques
Les données synthétiques sont récoltées par une famille d’outils qui réalisent des tests dans des conditions dites “de laboratoire”. L’idée est qu’ils reproduisent une visite utilisateur avec un contexte bien défini : bande passante et latence réseau, puissance CPU, dimensions et densité de pixels de l’écran, agent utilisateur… Leur principal intérêt est la comparaison, soit avec des pages concurrentes, soit dans le temps. Ce sont notamment des outils parfaits pour monitorer la performance et identifier rapidement d’éventuelles régressions de performance.
Comme évoqué précédemment, l’INP n’est toutefois pas disponible dans les rapports de ce type et pour cause : il s’agit de robots qui n’interagissent pas avec les pages comme le font les utilisateurs réels. La solution consiste à se tourner vers la métrique “Total Blocking Time” (“TBT”), dont la corrélation avec l’INP est très forte. Toutes deux sont effectivement très dépendantes du volume de JavaScript exécuté.
Les acteurs sont là aussi nombreux à proposer des outils de ce type, dont les plus populaires sont WebPageTest, GTmetrix, Treo ou encore Contentsquare Speed Analysis. Pour une vision exhaustive de la performance, il convient de monitorer à la fois les données terrain et les données synthétiques.
Les outils de développement de votre navigateur
Parce que vous êtes, après tout, vous aussi un internaute comme les autres, rien ne vous empêche d’utiliser votre propre navigateur web pour tester la performance de votre site et identifier d’éventuelles faiblesses côté INP. Les outils de développement de Google Chrome, aussi connus sous le nom de “DevTools”, disposent d’un outil extrêmement pointu conçu spécifiquement pour cela : l’onglet “Performance”, accessible via le menu puis “Autres outils”.
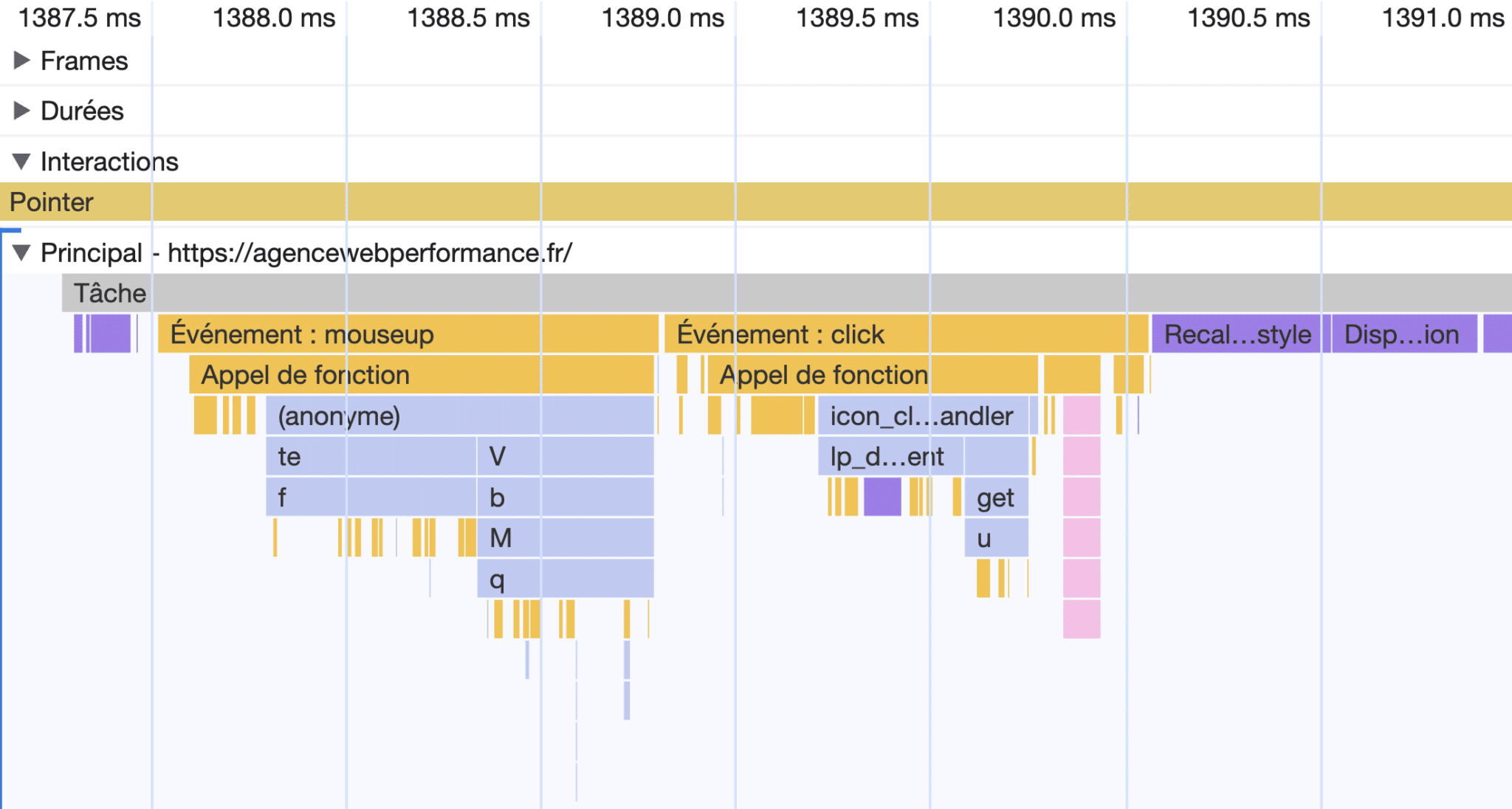
Son utilisation, et notamment la lecture de sa timeline et des « graphiques de flammes » (appelés ainsi en raison de leur aspect visuel), permet d’identifier le code JavaScript déclenché après chaque type d’interaction, ainsi que les opérations de repaint et reflow exécutées par le navigateur dans la foulée. Idéalement, la tâche principale doit être la plus courte possible et le nombre d’éléments déclenchés le plus faible possible.
Pour les profils techniques, c’est l’endroit idéal pour identifier LA fonction JavaScript qui pénalise votre INP. On notera d’ailleurs les efforts récents de Google pour rendre l’outil plus compréhensible (cf. les changements dans Chrome 121).
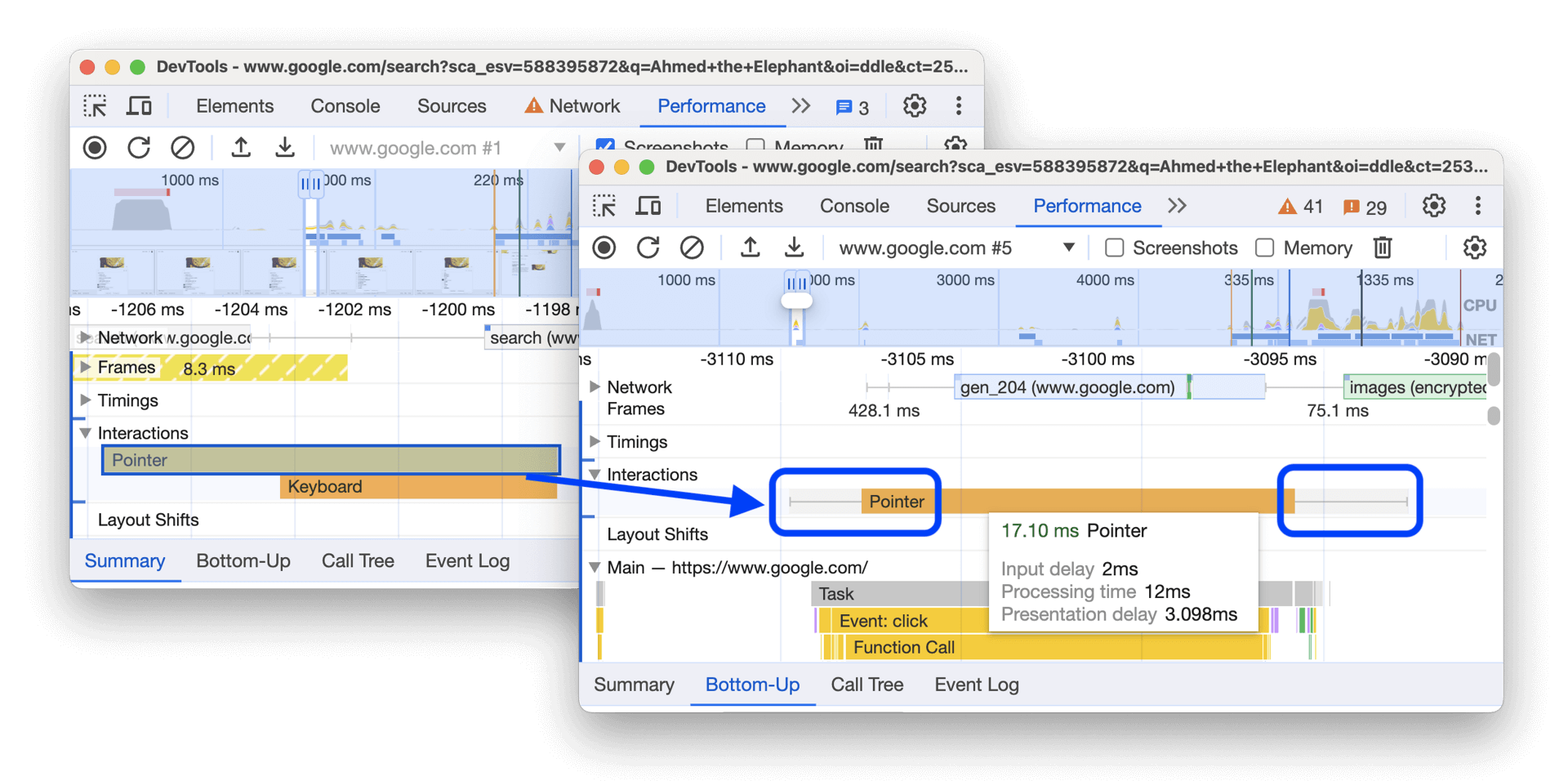
Nous ne rentrerons pas dans une lecture approfondie de cet outil dans la mesure où sa compréhension nécessite de solides bases en développement web front-end. Il existe fort heureusement une documentation illustrée voire, pour les plus motivés, des solutions encore plus poussées pour profiler de façon pointue les « traces » générées par les navigateurs. Il est en effet possible de les exporter au format JSON pour les visualiser via des outils comme Perfetto UI.
L’extension navigateur officielle Web Vitals
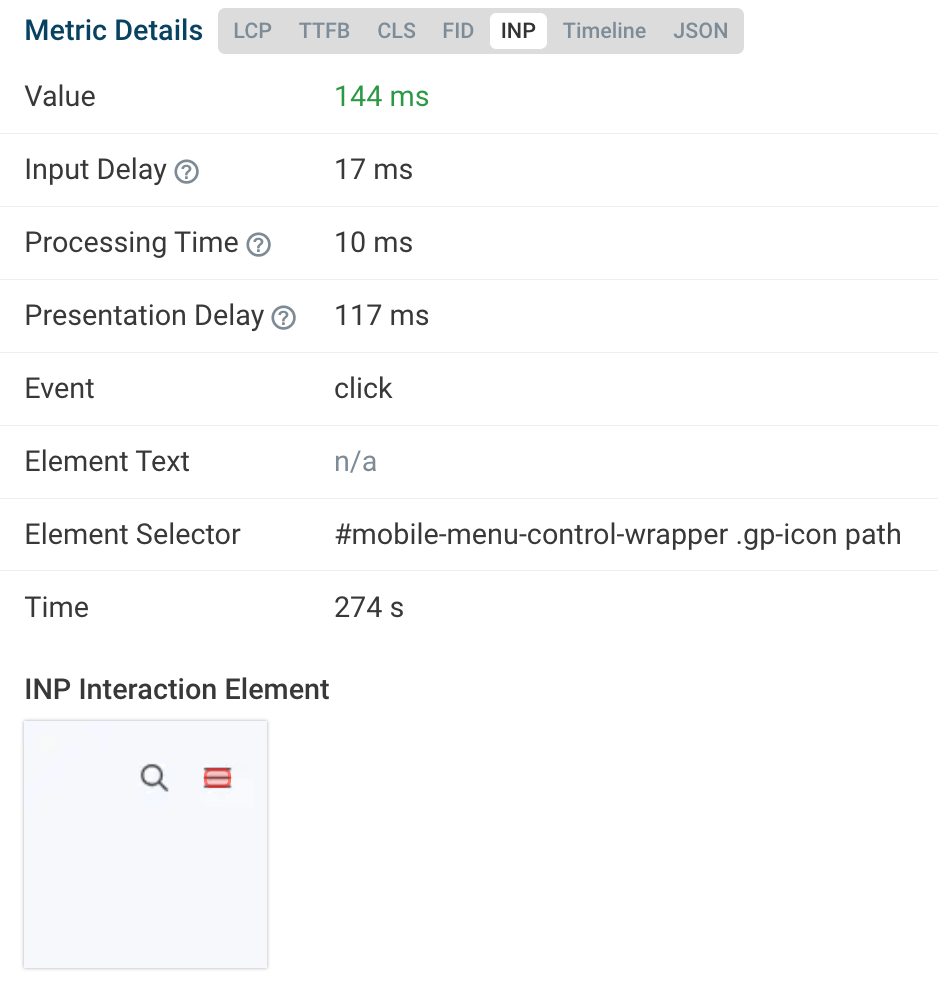
Pour les profils moins techniques, il existe une extension ”Web Vitals” pour Google Chrome. Après avoir activé le log des métriques dans la console via ses options, elle affiche en temps réel l’intégralité des données recueillies par l’API Web Vitals intégrée à Google Chrome. Chaque interaction avec une page logue ainsi un événement de type Interaction, avec une décomposition des trois étapes qui le constituent au sein d’un tableau.
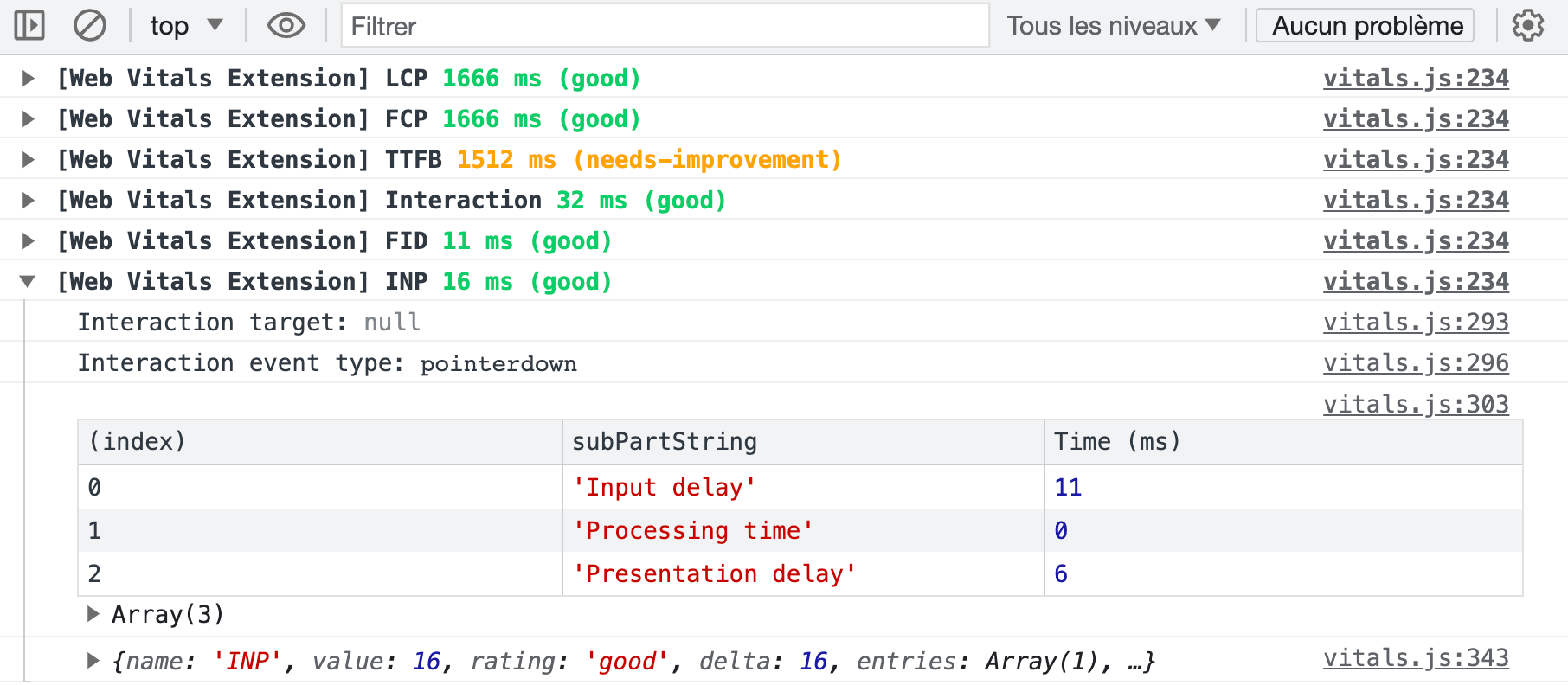
Dans l’exemple ci-dessus, on constate par exemple que les 16ms d’INP sont liés à un « input delay » (11 ms) mais aussi au délai de rendu (6 ms). Le seuil des 16 ms constitue d’ailleurs un cas d’école puisque sur un moniteur informatique classique au taux de rafraîchissement de 60 Hz, une nouvelle image est générée toutes les 16.66 ms (1000 ms / 60). Le navigateur n’étant pas en mesure de produire d’image avant le cycle de rafraîchissement suivant, l’INP est dans les faits rarement inférieur à 16 millisecondes.
Nous sommes maintenant capables d’accéder aux données de performance de nos utilisateurs, ce qui va nous permettre d’aller de l’avant en tentant de comprendre pourquoi certains utilisateurs font face à un INP élevé.
Votre site est-il aussi rapide que vos visiteurs l’espèrent ?

Qu’est-ce qui impacte l’INP ?
Exécution de JavaScript
Comme évoqué précédemment, l’INP est une métrique fortement sensible au volume de JavaScript présent dans une page. La métrique est directement corrélée au nombre et surtout au poids des fichiers .js appelés : non content de consommer de la bande passante au téléchargement, un script lourd consomme d’importantes ressources CPU et RAM pour s’exécuter. (rappelez-vous la corrélation entre la métrique INP et la quantité de mémoire vive disponible).
C’est la raison pour laquelle l’INP est aussi fortement corrélé avec les métriques suivantes :
- Long Tasks : les tâches qui saturent la consommation de ressources CPU durant plus de 50 millisecondes.
- Blocking Time : la fenêtre d’exécution des scripts qui pénalise effectivement l’interactivité. Si une long task dure 87 millisecondes, le Blocking Time sera de 37 ms (87 – 50 ms).
- Long Animation Frames (LoAF) : il s’agit d’une nouvelle API destinée à remplacer à terme les Long Tasks, un peu comme l’INP avec le FID. Elle offre un niveau de compréhension encore plus pointu des problématiques de réactivité pouvant impacter les animations.
Les JavaScript tiers, qui pèsent généralement plusieurs dizaines de kilo-octets, impactent tout particulièrement ces métriques. S’il fallait classer les familles les plus impactantes, de façon forcément un peu arbitraire, cela pourrait ressembler à cela :
- A/B Tests, qui modifient par nature le contenu des pages tôt dans la phase de rendu.
- Tags publicitaires comme Google Ads, Taboola et les scripts de régies réalisant de l’attribution en temps réel, ou « real time bidding », pour augmenter les revenus.
- Outils d’analyse comportementale comme Heatmap, Hotjar et Mouseflow.
- Chatbots, notamment les outils conversationnels reposant sur l’IA, souvent développés avec une maîtrise technique discutable.
- Vidéos embarquées, YouTube en particulier mais aussi Vimeo.
- Encarts sociaux qui, non contents de reposer sur des tags en JavaScript, chargent des iframe appelant à leur tour de multiples scripts et ressources.
Ces outils étant souvent utilisés conjointement et éventuellement appelés via un Tag Manager lui aussi coûteux, ils augmentent drastiquement l’INP, pénalisant l’Expérience Utilisateur et réduisant vos efforts pour passer les Core Web Vitals. Mais les scripts tiers ne sont pas les seuls à mettre en cause. Une poignée d’autres familles d’outils régulièrement intégrées à des thèmes ou stacks techniques peuvent elles aussi plomber l’INP :
- Les librairies de détection de fonctionnalités navigateur comme Modernizr ;
- Les outils de manipulation de dates comme Moment.js ;
- Certains polyfills mal développés ;
- … Et tous les frameworks JavaScript, du traditionnel jQuery aux très modernes React et Vue.
On notera enfin que certaines fonctionnalités basées sur des requêtes asynchrones (Ajax) peuvent facilement dépasser le seuil critique des 500 ms. Car entre le clic d’un utilisateur sur un bouton de vote (par exemple) et l’affichage à l’écran du nombre de votes mis à jour, le navigateur a réalisé un échange avec le serveur, qui a lui-même effectué une requête en base de données… Et cela prend rarement moins d’une demi-seconde.
Rendu navigateur
L’INP mesure les latences d’affichage suite aux interactions utilisateur. Comme nous l’avons vu précédemment, cela représente autour de 16 ms lorsque tout se passe bien, dont une grande partie liée aux étapes de la phase de rendu. Chacune de ces étapes est consommatrice de ressources CPU :
- Style : processus permettant d’identifier quels sélecteurs CSS correspondent à telle et telle partie du DOM (ex:
.body-footercible le pied de page du site…). - Layout : ensemble de calculs géométriques permettant de positionner les éléments sur un plan en 2 dimensions, à la fois de façon absolue dans le corps de la page, mais aussi les uns par rapport aux autres.
- Paint : processus de remplissage des éléments présents à l’écran : textes, couleurs, images, bordures, ombres… Le navigateur effectue également à ce moment des regroupements par « calques ».
- Compositing : affichage des différents « calques » en fonction de leur profondeur visuelle les uns par rapport aux autres. Cela concerne notamment les éléments positionnés en absolu avec des z-index.
Or, dans certains cas, cette phase de rendu peut être plus longue sans même qu’un JavaScript n’intervienne dans le processus. Ce cas de figure, bien plus courant qu’on ne le voudrait, est lié à la conception même des sites, et notamment aux aspects suivants :
- code html des pages : une structure DOM complexe avec de nombreux nœuds et de multiples imbrications successives augmente la consommation de ressources CPU, et donc le temps nécessaire aux calculs de mise en page ;
- CSS non optimal : des styles mal implémentés peuvent générer de multiples repaint et reflows à l’interaction. Les processus d’invalidation et de recalcul mis en oeuvre par le navigateur bloquent alors le rendu et font exploser l’INP.
Cette problématique de rendu non optimal est pénalisante durant la phase de rendu initiale bien évidemment, mais également par la suite. Lorsqu’un utilisateur interagit avec une page et qu’un élément est modifié au sein de cette dernière, le navigateur va effectuer de coûteux calculs afin d’estimer si d’autres éléments dans la page doivent eux aussi évoluer. Il va ainsi remonter l’arborescence du DOM jusqu’à l’élément racine, c’est-à-dire la balise <html>.
Comment améliorer l’INP ?
Fort de ces constats, nous savons qu’il faut travailler sur l’optimisation des JavaScript et du rendu. Mais qu’est-ce que cela signifie concrètement ? C’est ce que nous allons voir ensemble à travers des exemples malheureusement très répandus.
Optimiser son code JavaScript
Réduire le volume de JavaScript
La première démarche, tout aussi logique qu’efficace, consiste à réduire le volume de JavaScript appelé dans les pages. Ce n’est pas moi qui l’invente : il s’agit d’une recommandation officielle des gourous de la webperf oeuvrant au sein des équipes de Google. Il faut ici faire preuve de bon sens et supprimer tout ce qui n’est pas strictement utile, au risque de devoir parfois arbitrer entre nécessaire et “nice to have”.
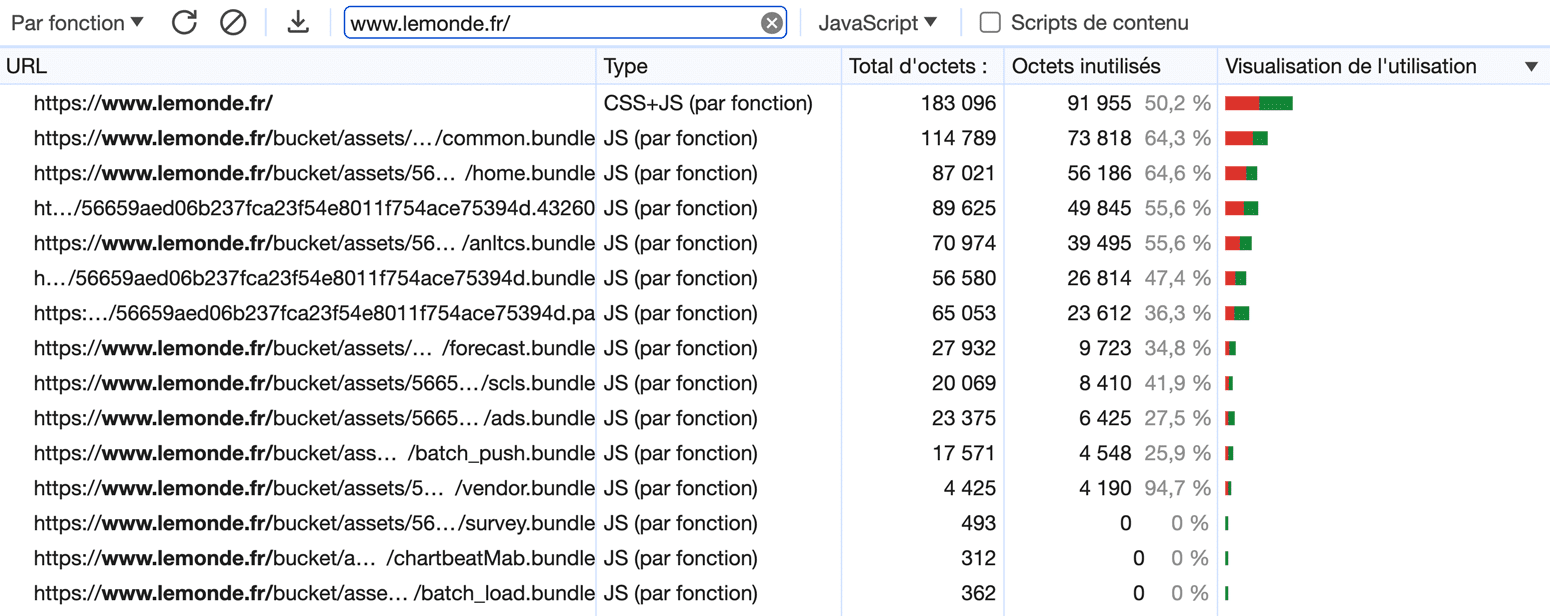
Chaque kilo-octet de JavaScript en moins se traduit potentiellement par une amélioration de l’INP avec, comme toujours, un avantage côté Core Web Vitals mais aussi Expérience Utilisateur. L’outil de prédilection pour initier cette mission d’identification est l’onglet “Couverture” des outils de développement (capture ci-dessus). Il permet en effet de détecter le pourcentage d’utilisation de chaque fichier JavaScript, propre comme tierce partie.
Cette démarche peut s’avérer complexe pour les développements reposant sur des gestionnaires de dépendances comme Composer ou npm, qui ont tendance à faire exploser le volume de JavaScript de façon assez opaque. Dans tous les cas, la logique consistera à utiliser les outils les plus spécifiques possibles, voire des développements sur-mesure, afin de s’assurer que le poids des bundles est aussi faible que possible.
Télécharger et exécuter les scripts en asynchrone
L’attribut html async, que l’on associe généralement aux appels de scripts pour en améliorer la performance, est à double tranchant. D’un côté, il rend les appels non bloquants pour le rendu, ce qui impacte positivement les métriques liées au temps de chargement comme le FCP, le LCP et le Speed Index. Mais en contrepartie, il rend leur exécution chaotique car si leur téléchargement est bien asynchrone, leur exécution intervient mécaniquement dans la foulée.
Concrètement, cela signifie que les scripts de type “async” peuvent bloquer le rendu d’une page à tout moment pour s’exécuter. Or, si vous vous rappelez bien, rendu navigateur et exécution de JavaScript sont les deux opérations les plus coûteuses pour le navigateur. Enchaîner des phases de l’une et de l’autre constitue un scénario catastrophe dans lequel Long Tasks, TBT et INP sont directement impactés.
La solution pour assurer un comportement asynchrone tout en ne bloquant pas le rendu est l’attribut defer. Ce dernier est non seulement asynchrone au téléchargement, mais il fait aussi en sorte que les scripts ne s’exécutent qu’une fois le document HTML entièrement analysé. Attention toutefois : l’attribut ne peut être utilisé qu’avec des appels externes via une balise html <script>. Passer un appel de Google Tag Manager en defer réclame ainsi un travail de remise en forme :
<script src="https://www.googletagmanager.com/gtm.js?id=XXXXXX" defer fetchpriority="low"></script>
<script>
window.dataLayer = window.dataLayer || [];
window.dataLayer.push({'gtm.start':new Date().getTime(), event:'gtm.js'});
</script>Scinder les fonctions longues
Les Long Tasks constituent un facteur majeur d’augmentation de l’INP. C’est notamment ce qui explique la forte corrélation entre cette dernière et le TBT. Or, les Long Tasks résultent généralement de fonctions JavaScript monolithiques : le navigateur n’étant capable d’exécuter du code qu’avec un unique fil d’exécution CPU, ce dernier arrive rapidement à saturation et ralentit l’intégralité de la page.
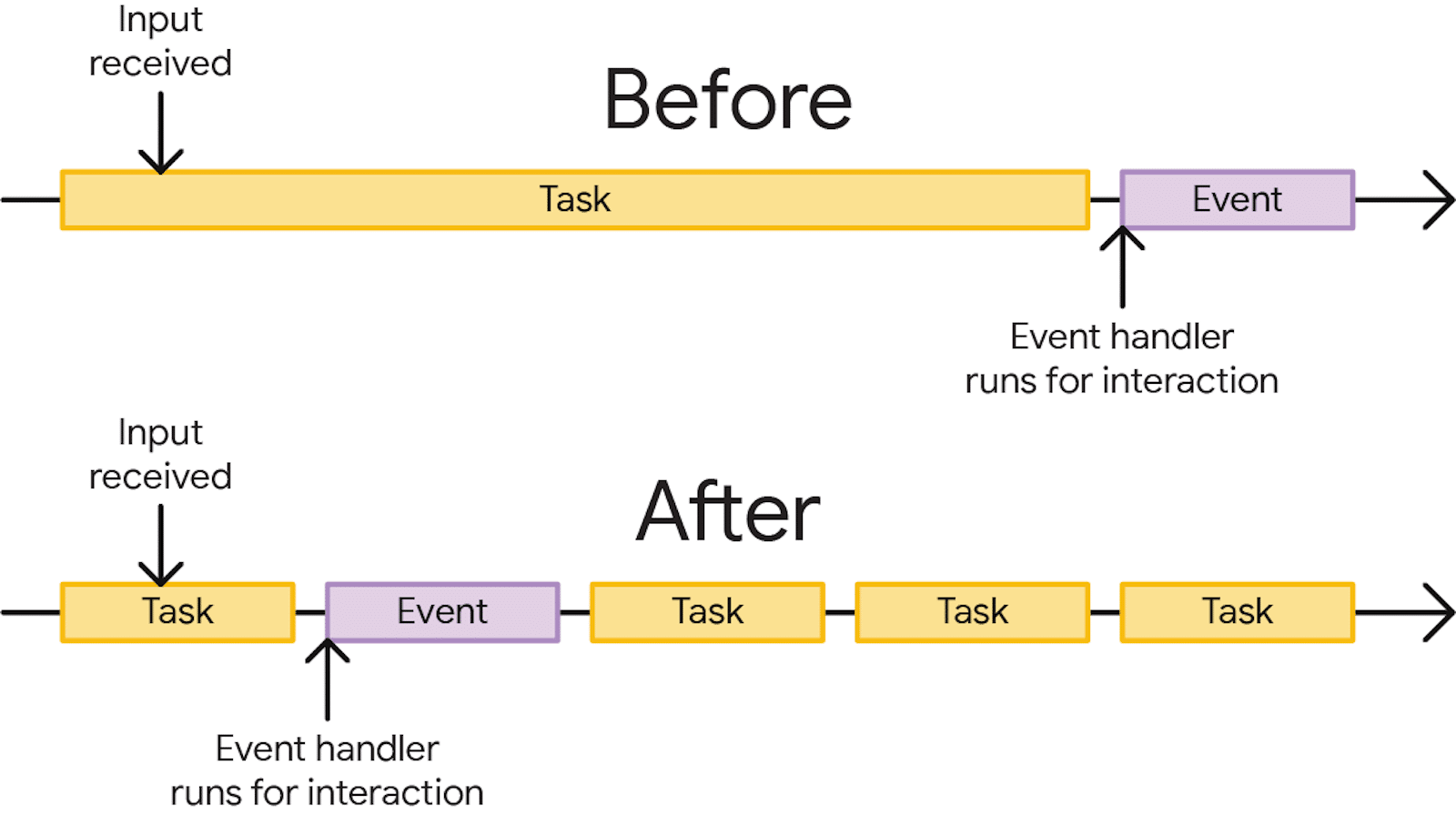
La solution consiste à découper les fonctions les plus lourdes en tâches plus courtes à exécuter, idéalement sous les 50 ms. Ces tâches doivent ensuite être appelées à la chaîne offrant, entre chacune, la possibilité pour le navigateur de gérer une éventuelle interaction utilisateur ou d’effectuer un rendu à l’écran. Quatre outils peuvent être mis à contribution pour cela.
setTimeout(), classique mais détourné de son usage
Traditionnellement destiné à retarder l’exécution d’une fonction après un laps de temps défini, setTimeout() permet aussi d’exécuter une tâche en la décorrélant de la tâche parente. On utilise pour cela une valeur de zéro, ce qui implique un déclenchement « immédiat » :
setTimeout(() => this._loadDelayedScripts(), 0);La méthode n’est toutefois pas la plus efficace dans ce rôle. Elle ne permet notamment pas de conserver de priorisation entre les différentes sous-tâches ainsi chaînées.
requestAnimationFrame(), idéal pour les rendus visuels
Plus moderne et mieux adapté aux contraintes du yielding, requestAnimationFrame() est une méthode JavaScript destinée à créer des animations fluides et efficaces. Son support est aujourd’hui universel mais on peut aisément basculer sur un classique setTimeout() en cas de non support par le navigateur.
La méthode permettant notamment de mettre à jour l’animation avant le prochain rafraîchissement de l’écran, c’est une option idéale pour réaliser du yielding de fonctions destinées à effectuer un rendu. Ce dernier sera automatiquement synchronisé avec le prochain cycle de rafraîchissement du navigateur, quelle que soit sa fréquence d’affichage. On peut l’utiliser ainsi :
window.requestAnimationFrame(() => {
document.querySelector('.share-buttons-toggler').remove();
});requestIdleCallback(), adapté aux tâches en arrière-plan
La méthode est utilisée pour planifier des tâches durant les périodes d’inactivité du navigateur, et ainsi dé-prioriser certaines opérations par rapport à d’autres. Elle est très efficace pour exécuter des tâches non urgentes sans compromettre la performance et la réactivité de la page.
requestIdleCallback() peut ainsi être utilisé pour réaliser du yielding de fonctions secondaires en étant certain de ne pas bloquer le thread principal. On peut l’utiliser de la façon suivante avec, en complément, le comportement de fallback optimal vers un classique setTimeout() :
if ('requestIdleCallback' in window) {
window.requestIdleCallback(() => this._loadDelayedScripts());
} else {
setTimeout(() => this._loadDelayedScripts(), 0);
}scheduler.yield(), optimal mais encore peu supporté
Il s’agit d’une toute nouvelle API de yielding native, disponible pour le moment uniquement sous Google Chrome en origin trial. La promesse est on ne peut plus séduisante puisque scheduler.yield() vise ni plus ni moins à permettre l’exécution de fonctions JavaScript sans qu’elles ne bloquent le rendu ou les interactions utilisateur.
La méthode repose sur la génération d’une file d’attente, dans laquelle elle vient ajouter les tâches à exécuter par la suite. Son principal avantage par rapport à setTimeout() est sa capacité à conserver la notion de priorité d’exécution. Les opérations non effectuées lors d’un cycle sont notamment réintégrées en tête de la file d’exécution, et non à la fin.
Il ne fait aucun doute que d’ici quelques années, cela constituera la principale solution pour dégorger un thread principal surchargé, et améliorer en conséquence l’INP.
Réduire le nombre d’Event Listeners
L’INP mesure les latences liées aux interactions utilisateurs. Ces dernières peuvent provenir de fonctionnalités natives comme l’activation d’une case de formulaire de type checkbox. Mais bien souvent, elles sont définies en JavaScript via ce qu’on appelle des Event Listeners. C’est eux qui permettent de déclencher une fonction JavaScript dite de “callback” suite à un clic, au toucher d’un écran ou à la saisie d’une touche du clavier.
Plus le nombre d’Event Listeners est élevé, notamment s’il cible des éléments génériques comme des balises <a> ou <input>, moins bon sera l’INP. À chaque interaction avec un élément associé à un Event Listener, le navigateur exécutera en effet le code JavaScript qui lui est associé. Pire encore, le comportement d’exécution par défaut de ces scripts est synchrone, ce qui accentue le risque de générer des Long Tasks.
Il est heureusement possible de modifier ce comportement pour adopter une exécution passive. On utilise pour cela l’argument “options” dans lequel est définie une clé passive avec la valeur true. Attention toutefois : cette implémentation ne permet pas de modifier le comportement par défaut du navigateur via la fonction JavaScript preventDefault(). Voici un exemple de code adoptant cette bonne pratique :
[].forEach.call(document.body.querySelectorAll("a[target='_blank']"), function(el) {
el.addEventListener(touchEvent, function(e) {
alert("Vous quittez notre site !");
}, {passive: true});
});Fournir du feedback aux interactions
Nous avons expliqué précédemment que certaines fonctionnalités reposant sur Ajax pouvaient avoir un impact négatif majeur sur l’INP. Dans ce cas spécifique, ce n’est pas uniquement le temps d’exécution des scripts qui impacte la métrique mais aussi et surtout la nécessité de réaliser un échange avec le serveur avant d’afficher quelque chose à l’écran. Du point de vue de l’utilisateur, cela reste un délai d’attente au même titre qu’une classique Long Task.
La solution pour éviter ce type de lenteurs est de systématiquement donner du feedback aux interactions via l’UI. Il s’agit là d’une bonne pratique élémentaire en termes d’UX mais malheureusement souvent ignorée. Avant même d’effectuer votre requête XHR ou d’exécuter votre fonction de callback, prévoyez l’injection d’un loader CSS animé voire même d’un bête texte “Chargement en cours…”.
Les champs d’application pour cette recommandation sont nombreux :
- Bouton d’ajout au panier qui vérifie la disponibilité du produit en arrière-plan avant validation ;
- Bouton de vote positif ou négatif qui incrémente un champ en base de données avant d’afficher le nombre actualisé ;
- Bouton “Charger plus…” pour gérer une pagination dynamique.
Reporter l’exécution
Il arrive souvent que, même en mettant scrupuleusement en oeuvre les bonnes pratiques développées précédemment, une page ou un site web dans sa globalité continuent à souffrir d’un INP trop élevé. Si tous les JavaScript présents sont effectivement utilisés, il reste un dernier recours : le report d’exécution. L’idée est simple : plutôt que d’exécuter l’intégralité des scripts au chargement initial, on n’exécute que ceux strictement nécessaires au fonctionnement du site dans un premier temps.
Les autres scripts, notamment tiers, ne sont téléchargés et exécutés que plus tard. En scindant l’exécution en deux fenêtres distinctes, on réduit fortement les risques de saturer les ressources CPU disponibles. Plusieurs comportements sont ici possibles :
- retard pur et simple via un
setTimeout(), généralement de 3 à 5 secondes après l’événement JavaScriptDOMContentLoaded; - déclenchement sur action utilisateur de type clic, scroll, saisie au clavier (…) via l’ajout d’un Event Listener (ma solution préférée) ;
- déclenchement sur un seuil de scroll dans la page ou l’entrée d’une zone au sein du viewport actif, utile par exemple si un script lourd n’est utilisé qu’en pied de page.
Plutôt simple à mettre en place, cette fonctionnalité est même disponible de façon intuitive pour les utilisateurs du CMS WordPress grâce à des extensions comme WP Rocket et Perfmatters.
Mettre en place des façades
Il arrive parfois que certains scripts très lourds ne soient utilisés que par une minorité de visiteurs. C’est typiquement le cas d’un Chatbot, dont l’infobulle occupe fièrement le coin inférieur droit du navigateur mais avec lequel seuls 0,5% des utilisateurs interagissent. Ou encore d’un embed vidéo, qui ne sera majoritairement pas lu. La question à se poser ici est : doit-on accepter de dégrader l’expérience de l’intégralité de nos visiteurs pour répondre aux attentes de seulement 0,5% d’entre eux ?
C’est à cette problématique que répond une “façade”. Concrètement, cela consiste à reproduire aussi fidèlement que possible les éléments d’interface auxquels l’internaute est habitué, comme une bulle flottante pour un Chatbot ou une miniature de couverture avec un bouton de lecture pour un embed vidéo. Le script correspondant n’est téléchargé et exécuté que lorsque l’utilisateur interagit avec l’élément déclencheur, en toute transparence.
Idéale pour les deux cas présentés, cette solution nécessite toutefois davantage de développements. Le HTML et le CSS doivent être intégrés pour coller au plus près du résultat final alors que côté JavaScript, un Event Listener doit être associé aux déclencheurs pour charger en arrière-plan le script le moment venu. Voici un exemple de script utilisé pour charger un formulaire Typeform :
var typeform_loaded = false,
typeform_load = function() {
return new Promise(function(resolve, reject) {
if(typeform_loaded === false) {
const s = document.createElement('script');
let r = false;
s.src = "https://embed.typeform.com/next/embed.js";
s.async = true;
s.onerror = function(err) {
reject(err, s);
};
s.onload = s.onreadystatechange = function() {
if (!r && (!this.readyState || this.readyState == 'complete')) {
r = true;
typeform_loaded = true;
resolve();
}
};
const t = document.getElementsByTagName('script')[0];
t.parentElement.insertBefore(s, t);
}
});
};
[].forEach.call(document.body.querySelectorAll(".load-typeform"), function(el) {
el.addEventListener("mouseenter", typeform_load, {passive: true});
});Se reposer sur un Service Worker ou un Web Worker
Lorsque certaines tâches lourdes doivent être exécutées via JavaScript, il est enfin possible d’opter pour une implémentation différente. Bien qu’ils répondent à des cas d’usages très différents, les Service Workers et les Web Workers permettent tous deux d’exécuter des scripts de façon asynchrone en utilisant un fil d’exécution processeur différent de celui des pages.
L’un des outils les plus ambitieux en la matière est Partytown. En détournant ingénieusement certains mécanismes du navigateur, il rend possible l’exécution de scripts tiers dans un Web Worker avec un support complet des API natives. Il est notamment compatible avec Google Tag Manager, Google Analytics, Facebook Pixel ou encore Hubspot, tous connus pour leur impact négatif sur le Blocking Time et l’INP.
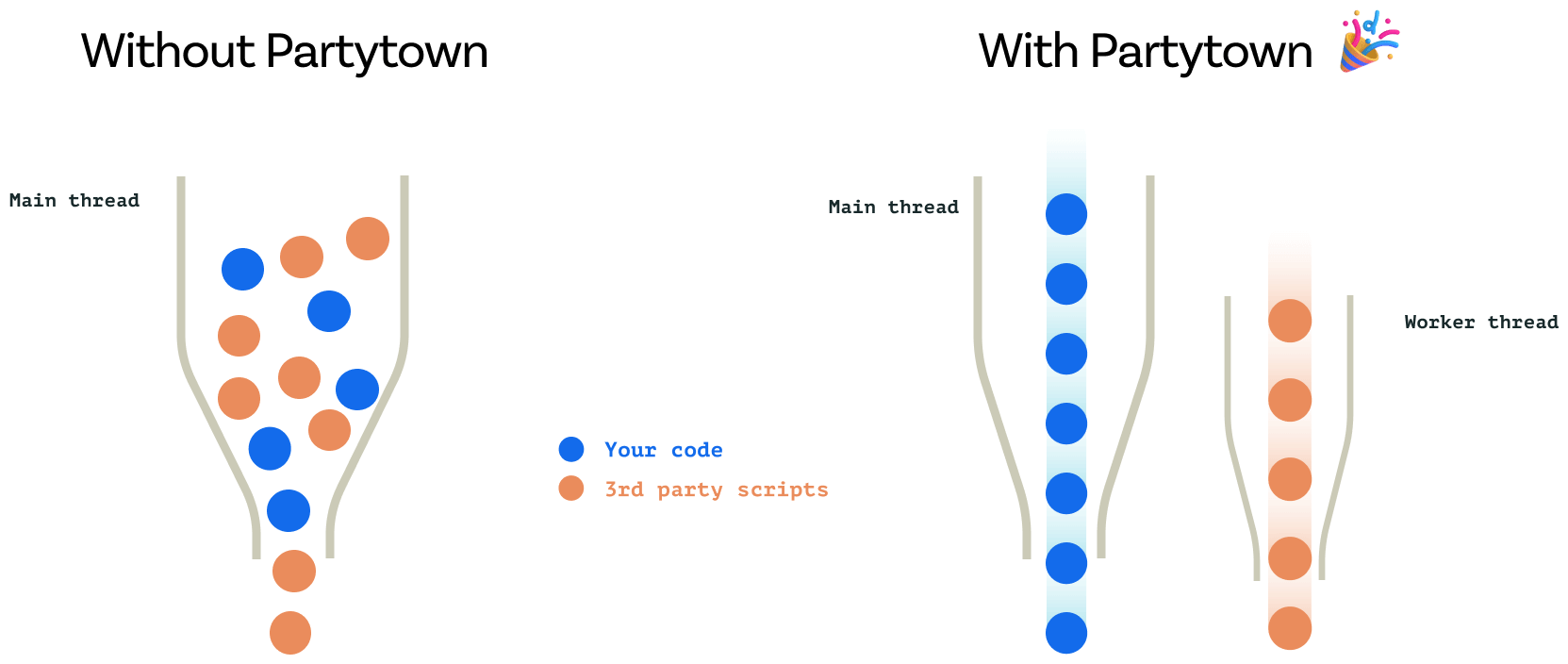
Il en résulte une bien meilleure interactivité des pages en elles-mêmes. Attention toutefois : les Service Workers présentent eux aussi certaines limites, la plus importante étant une latence moyenne de 300 millisecondes au chargement initial.
Éviter l’utilisation des méthodes de type alert()
Les méthodes JavaScript alert(), prompt() et confirm() sont un moyen simple et efficace d’afficher un message ou de demander une confirmation à un utilisateur. Cependant, elles s’exécutent de manière synchrone en bloquant le fil d’exécution principal de la page. Concrètement, cela signifie que l’interaction est considérée comme « en cours » tant que l’utilisateur n’a pas cliqué sur le bouton de fermeture.
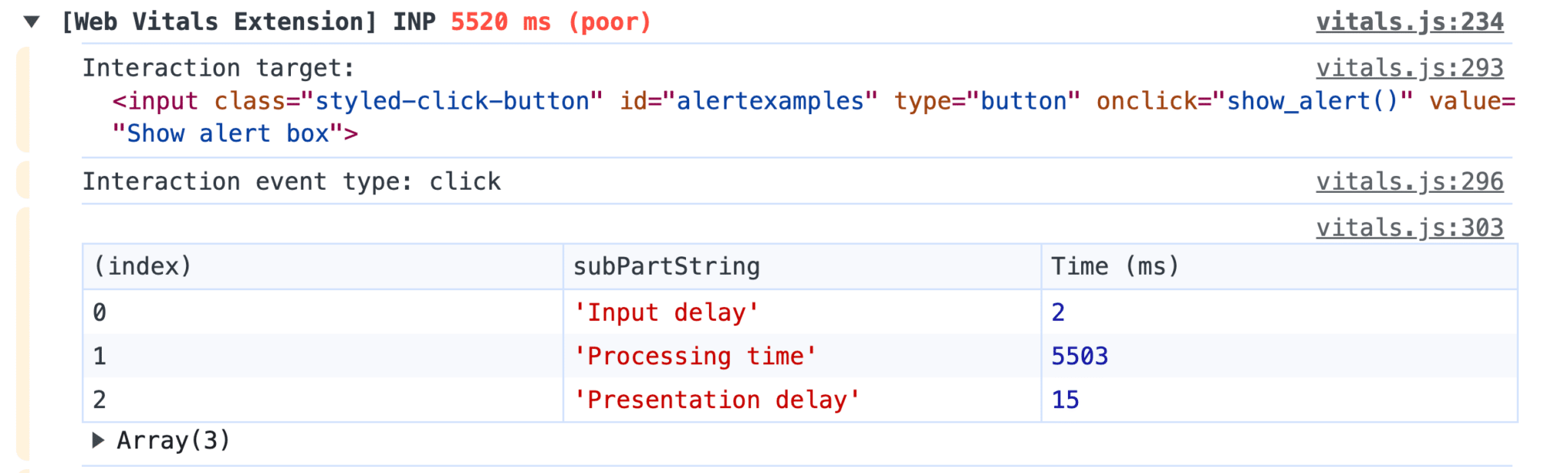
Ce comportement pouvant pénaliser très fortement l’INP sans pour autant représenter une frustration pour les utilisateurs, il est fort probable qu’une future mise à jour des Core Web Vitals change la donne. Mais pour le moment, cela reste un point de vigilance crucial pour maîtriser l’INP.
Optimiser son CSS
Limiter l’utilisation du sélecteur universel
JavaScript n’est heureusement pas systématiquement le seul fautif lorsque l’INP grimpe en flèche. Cela peut en effet aussi être lié à certains choix techniques de votre intégrateur, d’un développeur front-end ou du créateur de votre CMS, thème ou extension. L’une des erreurs les plus classiques est la sur-utilisation du sélecteur CSS universel, matérialisé par un astérisque (*).
Lorsque le moteur d’interprétation CSS du navigateur rencontre un sélecteur reposant partiellement ou totalement sur ce sélecteur, il n’a d’autre choix que de tester sa pertinence pour l’intégralité des nœuds du DOM. Une opération coûteuse en ressources CPU, et donc potentiellement génératrice de latences pénalisantes côté INP. Fuyez donc ce sélecteur comme la peste en privilégiant systématiquement des sélecteurs plus précis, idéalement une classe.
On notera au passage une exception très largement implémentée sur les sites récents : l’utilisation de ce sélecteur pour activer globalement le mode de rendu CSS border-box. Cela se traduit concrètement par la présence d’une déclaration CSS de ce type :
*,::after,::before {
box-sizing: inherit
}Utiliser des animations performantes
Parler d’interactions sans évoquer les animations CSS serait un grave manquement aux règles de bienséance du web. D’autant plus que côté INP, elles peuvent elles aussi jouer un rôle non négligeable. C’est le cas dans deux cas de figure bien distincts mais tout aussi pénalisants :
- les animations continues, comme un arrière-plan de page animé par exemple. Elles peuvent générer une consommation de ressources élevée et constante qui va directement impacter l’INP tout au long de la navigation des utilisateurs ;
- les animations au survol comme un zoom, un changement de couleur d’arrière-plan ou l’application d’un
box-shadow. Elles peuvent elles aussi impacter négativement l’INP, mais souvent de façon moins marquée en raison de leur activation ponctuelle.
Pour éviter d’impacter négativement la performance, la première bonne pratique consiste à utiliser exclusivement des animations basées sur transform et opacity. Si vous croisez du width, du margin ou du top au sein d’une déclaration @keyframes, vous avez du souci à vous faire : il s’agit d’animations “non composées” problématiques. Cela obligera le navigateur à repasser par les phases de Layout, Paint et Compositing présentées précédemment.
Il ne s’agit pas d’une décision arbitraire mais de la conséquence d’un choix architectural des navigateurs : opacity et transform profitent nativement de l’accélération matérielle, et sont donc traités par le GPU et non par le CPU. Concrètement, ces animations seront donc non seulement bien plus fluides visuellement, mais elles ne seront pas non plus génératrices de Long Tasks.
Soulager le rendu initial
Quels que soient le nombre de scripts et d’animations CSS dans une page, un DOM non optimisé, c’est-à-dire volumineux et profond, pourra impacter négativement l’INP. Car durant le rendu initial comme lors d’interactions utilisateur, les calculs du moteur de rendu seront plus coûteux, et donc plus longs. Lorsqu’on le peut, notamment lorsqu’on développe un site sur-mesure, il est ainsi essentiel de veiller à générer un volume de DOM minimum.
Un tel objectif est toutefois généralement difficile à atteindre, et les seuils de 800 et 1400 nœuds que l’on considère comme les paliers moyen et élevé à ne pas dépasser, sont rapidement atteints. Fort heureusement, cela ne signifie pas pour autant que tout est perdu. Il existe en effet des propriétés CSS permettant au navigateur d’être plus efficace dans le rendu. L’une des plus puissantes est le “Lazy Rendering”, ou “rendu fainéant” en français.
En attribuant la valeur auto à la propriété CSS content-visibility, le navigateur va tout simplement ignorer la portion de page concernée pour n’en effectuer le rendu qu’une fois cette dernière à proximité du viewport. Avec une contrepartie majeure toutefois : puisque le navigateur n’effectue aucun calcul de rendu, il est nécessaire de lui fournir les dimensions finales sous peine de générer des défilements saccadés. Cela se fait simplement via la propriété CSS contain-intrinsic-height.
Pour rendre cela plus parlant, voici un exemple de mise en place de Lazy Rendering sur un pied de page. Les footer sont d’excellents candidats car ils comptent souvent plus de 100 nœuds DOM tout en étant, par définition, visibles assez tardivement et par une minorité de visiteurs.
.site-footer {
content-visibility: auto;
contain-intrinsic-height: 400px;
}
@media(min-width: 768px) {
.site-footer {
contain-intrinsic-height: 250px;
}
}Soulager le rendu aux interactions
Si le Lazy Rendering est pertinent pour améliorer les temps de rendu au chargement initial, et donc mécaniquement l’INP, il n’aide en rien dans la suite des sessions de navigation. Pour ce faire, il existe une seconde fonctionnalité native baptisée “CSS containment”, ou “compartimentation CSS” en français. Cette dernière permet de limiter les recalculs du navigateur lorsqu’un élément d’interface change : défilement d’un slider, ouverture d’un sommaire ou simple changement d’une couleur d’arrière-plan.
Mettre en place une compartimentation CSS permet d’influencer la façon dont le navigateur traverse l’arborescence du DOM lors d’une modification visuelle, comme évoqué précédemment. Concrètement, cela consiste à définir, via des sélecteurs CSS, une sorte de barrière étanche qui va empêcher le navigateur de remonter au-delà. Fort de cette information, il ne cherchera plus à savoir si une modification au sein du conteneur peut impacter ses parents.
Puisqu’un bon exemple vaut mieux que de longues explications, voici un extrait de code qui permet de cloisonner les sections présentes dans la zone de contenu d’une page. On notera que pour un impact maximal, la propriété CSS contain doit prendre la valeur content mais que bien souvent, pour des questions de compatibilité, on est contraint d’utiliser la valeur layout style, moins complète et donc moins efficace.
#main-area > section {
contain: content;
}Réduire les interactions sur les zones « mortes »
Un dernier outil CSS peut permettre de maîtriser davantage certains comportements relatifs aux interactions, et donc impacter la façon dont l’INP est calculé. Il s’agit de la propriété pointer-events qui, associée à la valeur none, est capable de rendre une zone du DOM non interactive. Il s’agit d’un outil à manipuler avec des pincettes tant il peut, mal utilisé, pénaliser l’Expérience Utilisateur.
Concrètement, le déploiement de pointer-events: none; sur un div génèrera systématiquement des interactions très courtes (autour de 16 ms) avec, en contrepartie, l’impossibilité de déclencher toute action en JavaScript comme en CSS. Il existe peu de cas de figure où une telle implémentation peut réellement apporter de la valeur ajoutée.
Que faire si l’INP reste problématique après optimisation ?
Si l’INP demeure problématique malgré l’implémentation des recommandations détaillées précédemment, cela doit vous conduire à reconsidérer en profondeur les choix techniques et la stack front-end. Cela implique de réévaluer non seulement les frameworks et outils utilisés, mais également l’architecture globale du site.
Pour être totalement explicite, l’amélioration de l’INP peut nécessiter la refonte complète d’un site. Une telle décision ne doit pas être prise à la légère, mais elle peut s’avérer indispensable pour répondre aux attentes modernes en matière de performance web. Il est crucial de sélectionner des technologies et des outils qui non seulement répondent aux besoins actuels, mais sont également capables d’assurer la réactivité exigée par l’INP.
Le challenge est notamment corsé pour certains frameworks JavaScript de type SPA, même si la plupart ont fait des bonds significatifs sur cet aspect dans le cadre de leurs dernières mises à jour.
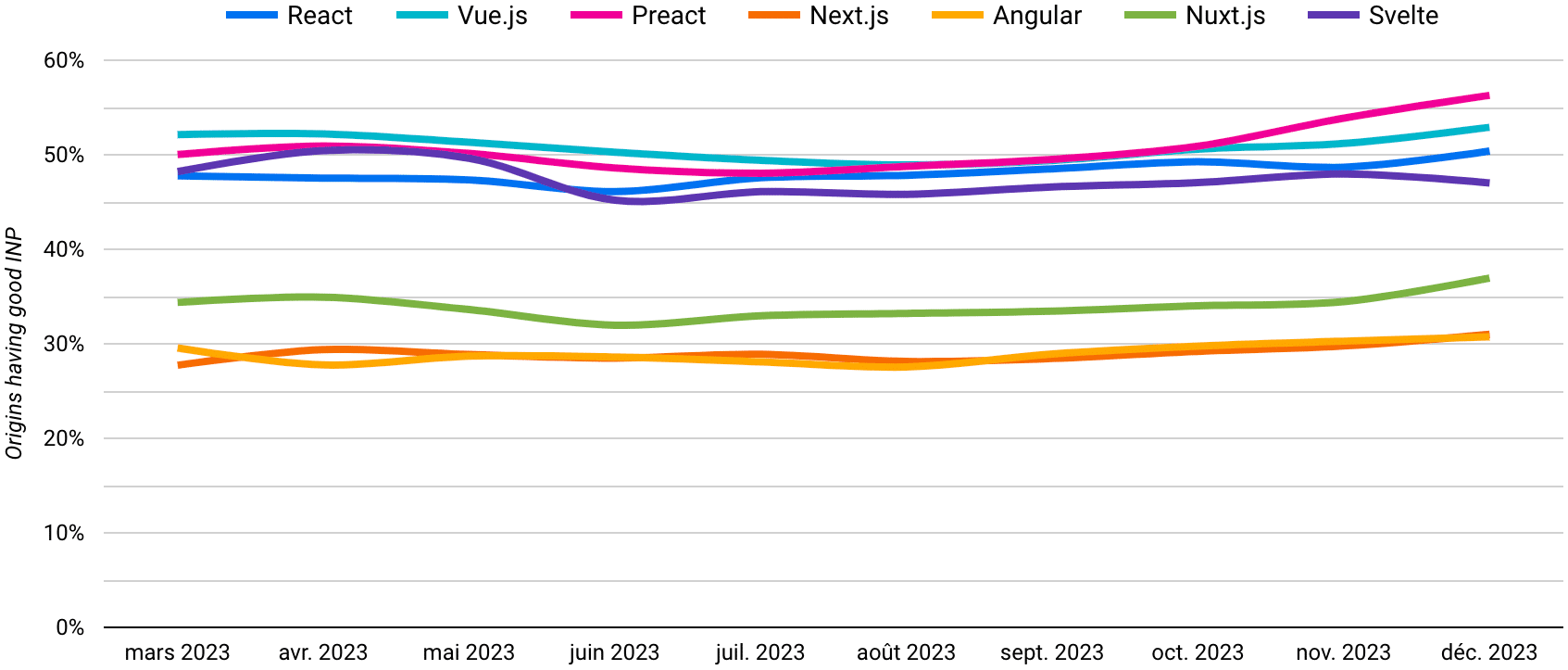
Historiquement, les Core Web Vitals ont mis l’accent sur des métriques potentiellement optimisables quel que soit l’environnement, comme le LCP et le CLS. De quoi permettre aux éditeurs de sites de s’adapter à ces nouvelles contraintes et de déployer une démarche d’amélioration continue. L’INP, en revanche, marque un tournant, pouvant conduire à une rupture dans les pratiques établies.
C’est une métrique exigeante, qui reflète l’évolution des attentes des utilisateurs envers des expériences web toujours plus interactives et réactives. La maîtrise de l’INP est donc non seulement un indicateur de performance technique mais également un signe d’adaptation aux tendances actuelles et futures du web.
La web performance à l’avenir
J’espère que cette aventure à travers les dédales de l’INP aura satisfait votre curiosité et, pourquoi pas, suscité de l’intérêt pour la discipline. Ce qu’il faut en retenir, c’est qu’au cœur de la démarche de Google réside une mission claire : mesurer avec le plus de justesse possible ce que ressent réellement l’internaute lorsqu’il navigue sur une page web. Imaginez ces métriques comme des baromètres qui tentent de capter le plus fidèlement possible notre confort et notre aisance lors de nos explorations en ligne.
Ce qu’il faut en retenir également, c’est que rendre la navigation de nos utilisateurs plus agréable n’est pas qu’une belle initiative. C’est également un excellent levier pour le business et la réputation d’un site. Que l’on vende des produits en ligne, que l’on propose des contenus publicitaires ou toute autre chose, s’assurer que le visiteur navigue avec aisance et plaisir s’avère être un choix stratégique, judicieux et toujours bénéfique.
Pour les sceptiques comme pour ceux qui ne jurent que par les Core Web Vitals, rappelons la place réelle de la web performance : l’un des très nombreux facteurs parmi les centaines entrant en jeu dans l’insondable algorithme de classement de Google. L’important à garder en tête, c’est qu’elle permet de distinguer les sites de qualité parmi une multitude, cette dernière étant toujours plus large et qualitative avec l’utilisation croissante de l’intelligence artificielle et d’outils comme ChatGPT. La webperf agit tel un phare, guidant les utilisateurs à travers la tempête vers des contenus qui valent réellement la peine d’être explorés.
Maintenant que l’INP est intégrée aux Core Web Vitals de Google, le plus dur reste pour beaucoup à venir. Car si certains ont d’ores et déjà eu l’opportunité d’ajuster, d’améliorer et de peaufiner la performance de leurs pages web en mettant à profit la période Expérimentale, d’autres sont encore très loin d’atteindre les 200 millisecondes.
Face à ce défi, vous pouvez choisir de mettre à profit les pistes détaillées précédemment, ou bien de confier ce chantier à des experts comme l’Agence Web Performance. Nous ne nous concentrons pas uniquement sur l’INP, mais sur l’ensemble des facteurs qui influencent la performance et l’expérience utilisateur. Notre méthodologie rigoureuse et nos outils pointus offrent l’assurance que votre site web n’est pas seulement conforme, mais qu’il excelle dans tous les aspects de la performance web.


